Linux中的GOT和PLT到底是个啥?
0x00 Intro
本文以Ian Wienand的博客为蓝本,我在必要的地方予以增补、解释以及再实验,希望读者对PLT和GOT有一个初步的、相对完整的认识。
0x01 The Simplest Example
原文的标题是“PLT and GOT - the key to code sharing and dynamic libraries”,可见PLT和GOT对代码复用以及动态库的关键作用。
共享库(shared library)是现代操作系统的组成部分,但其内部机制却很少有人去了解。当然,有很多解释共享库机制的文章,希望本篇博客能为这方面的知识体系加一把火。
OK,我们从最起始部分讲起—-在二进制文件(比如object file)中会有一段叫relocations的部分,这部分的内容在链接时候(link time)再进行敲定确切的值,注意链接可以发生在运行前(称为静态链接,toolchain linker),也可发生在运行时(称为动态链接,dynamic linker)。具体relocations部分中的内容就是在讲:“确定X这个符号(symbol)的值,然后把这个值写到二进制文件的Y偏移处”。每一条relocation都有确定的类型(定义与ABI文档中),从而确切地说明每个类型的值到底该如何敲定。
如下为最简单的例子:
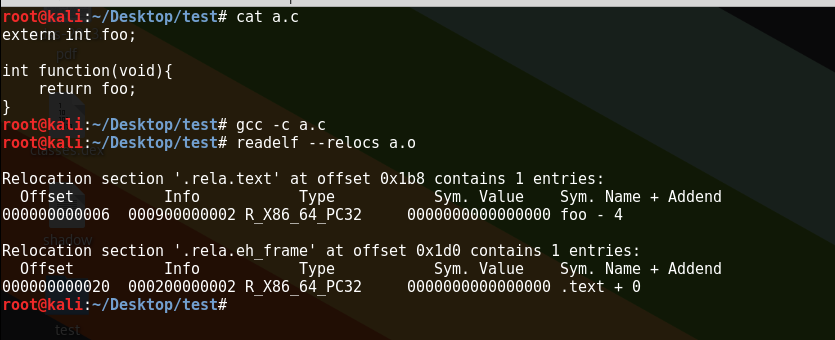
我们可以看到”foo”这个符号的Sym.Value是0,说明在把a.c编译成a.o的时候,“foo”这个符号的值还不知道,所以编译就在Sym.Value处先写0,然后在Type这个位置写上R_X86_64_PC32,从而告诉之后要进行link的链接器:”在最终生成的可执行文件的.text部分的0x6这个偏移位置,patch上foo这个符号的地址值”。如果我们看一下a.o这个对象文件的.text部分0x6这个位置,我们会看到如图绿线部分:
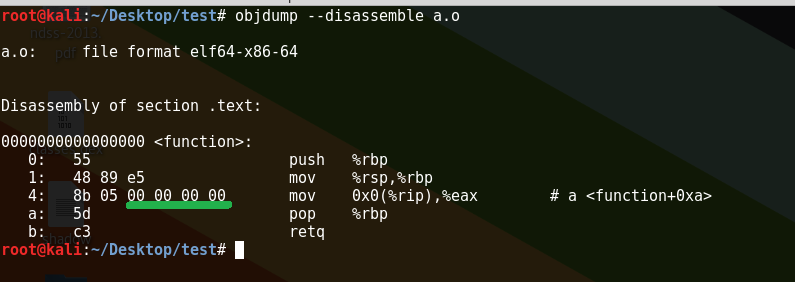
觉得刚刚看到这张图片,可能就会有些刚刚接触这些概念的同学就有些懵了。别急,我一点点地讲这张图。首先一个二进制可执行文件可被划分为多个部分:
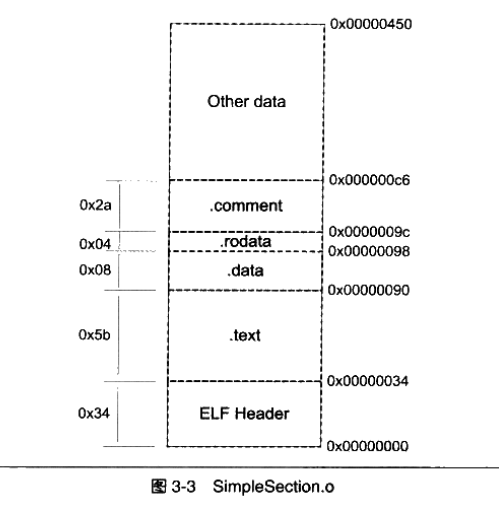
这张图片截取自《程序员的自我修养》这本书,真心希望像搞懂“程序是如何跑起来的?”这种问题的同学,去读一下这本书,你会觉得很值的,这是一个很本质的问题,而书中解释得那样的清晰,总之,强烈推荐!
.text部分会放着这个二进制文件的执行代码,所以当我们用objdump进行反汇编的时候,就会看到a.o这个二进制文件的.text部分的机器码,前两条指令用于布置好栈空间(这部分可参考William Stallings的Computer Security那本书的第十章)不是本文的重点,后两条指令用于清理栈空间,并返回调用函数,也不是本文重点。重点在第三条语句,它在.text的Offset 0x4处。我们可以看到,a.o仅仅是一个经过编译后的object file,所以其中的真实值并没有敲定,从而看到绿线处暂时填4个00。
好,下面我问一个问题:当CPU执行到0x4出这句指令时,%rip(即PC)的值为多少?两个选项,A. 0x4 ;B. 0xa。答案:B。参考CSAPP第四章,截图如下:

其实,计算机在执行一条指令需要一个指令周期,不同的CPU架构的指令周期可以分为不同阶段,上图中我们可看到Intel x86架构CPU的指令周期分为:取指,译码,执行,访存,写回,PC update,这六个阶段。这里,我说一下我对PC的理解,图中绿线部分,vaIP对应%rip寄存器,%rip趋向于一种实际意义层面上的理解,而PC更趋向于一种意向意义层面上的理解。具体来说,在PC update阶段,CPU才去关注”我要去执行的下一条指令在哪里”(通过关注%rip中的值),而在CPU关注“下一条指令在哪里”之前(即PC update周期之前),在Fetch阶段,%rip寄存器按图中绿线的指示,其值便已经改变了,(改变方法是:当前指令的PC加上当前指令的长度,图中subl %edx, %ebx这条指令长度为2,所以vaIP被赋值为PC+2)。简单理解,%rip就是PC,在CPU这执行当前指令时,%rip便已经指向了下一条指令所在的地址处了,只是到了PC update环节,CPU才去看%rip的值(当然在Execute环节,CPU也可以使用%rip,但并不是为了程序的执行流而去关注%rip,此时就纯粹那%rip作为一个存值的寄存器来使用,而且此时的%rip已经指向下一条指令了,这也便是我第二个问题的解释)。
对于我上述理解的支撑材料是,王爽老师那本《汇编语言》的第二章的2.10节有关CPU如何执行一条指令的一系列图示。这里由于图示很长,我就不粘贴了,简单讲就是,CPU还没开始执行具体指令的时候,IP的值便已经指向下一条指令了。
好了,说了这么多,我想,我可以开始解释0x4处这条指令的意思了,就是将0x0 + %rip这个地址处所存的值,赋给%eax。而此时,%rip的值,根据我们上面问的问题的描述,应为0xa(下一条指令的地址),所以这条指令的含义进一步解释为,以%rip为基址,以0x0为偏移的内存地址处取内容,给到%eax。而此时偏移之所以为0x0,是因为还没有经过链接过程,所以真实的偏移地址还没有敲定,所以暂时写0x0。
明白了该指令的含义,但这句到底是在干啥啊?我们回头看一下a.c源码,foo是一个extern(外部)的int型数据,函数function的返回类型也是一个int型数据,其内容为将foo给return出来。我们知道a.o仅仅是经过编译的,编译器会说:“我不知道foo这个外来int会来自于那个.o文件,那是链接器的活!我就姑且把foo所在的内存地址偏移定为0x0”。
经过link之后,该偏移会被patch成foo的真实地址偏移。
0x02 Position-Independent Code
接着上面,如果foo这变量的值出现在其他的对象文件(比如b.o)中,那么便可以通过静态链接,来将a.o和b.o链接到一个executable中,而在executable中,原来a.o中relocations部分foo相关的条目便可以去掉了,因为foo的真实地址,已经被linker,根据b.o中有关foo的信息,给patch好了。但是,“ there is a whole bunch of stuff for a fully linked executable or shared-library that just can’t be resolved until runtime. ”,对于一个executable或者共享库,有许多事,只有到了运行时(runtime)才能敲定。比如,我们即将讲到的位置无关代码(position-independent code ,PIC)。
首先,我们先看一下位置相关代码(清晰起见,用作者的32位机的例子即可):
|
|
可见ls这个可执行文件,它有一个fixed的加载位置,即代码部分(其flag是R和E)必须加载到0x08048000(注意这个是物理地址),而数据部分(其flag是R和W)必须加载到0x0805ff88。这种位置相关的代码,固然有其好处,不用再在runtime的时候去算一些地址信息什么的了,因为地址都是fixed。
不过,这种fixed地址对shared library(.so文件)并没有好处。so文件的一个核心观点就是拿过来,加载到任意一段物理内存上就用。而如果so文件必须被加载到一个特定的地址上才能运行的话,我们可能就得把计算机上所有so文件都给一个特定的加载地址,以保证在使用这些so文件时不会有重叠(overlap),这其实也是预链接(prelinking)要做的事。但对于一个32位机,你这么做的话,马上内存就分配完了。所以,还是得考虑一种位置无关代码的方案。实际上,当我们去检查一个so文件的时候,会看到它们并不会指定一个特定的加载基地址(可见R E flag标示的代码部分的物理地址为0,即不会指定加载基地址):
|
|
共享库的第二个目标就是代码重用(code sharing)。对于shared library,我们需要让它的code段保持不变,如果变了的话,那么100个进程调用这段代码,因为code段会变的原因,就要占用100段物理内存空间,这肯定不是我们想要的,所以要保持so文件中code段不能动,从而只需将这个code段加载到一个特定的物理地址处,每个调用该so文件的进程的虚存指向这个物理地址就可以了。还有就是,so文件中data段的相对位置也不能变,从而使写死的code段,能够通过相对位置来找到data段(上面的headers中,我们可以看到data段的offset是0x023edc)。这样,通过virtual memory的神奇机制(同一虚拟地址,可以映射到不同的物理地址),“every process sees its own data section but can share the unmodified code”。于是对于每一个进程,要找到其特有的data段时,使用简单的数学即可:我当前的地址(code段某处) + 已知的相对位置 = 我索引的data段 。
0x03 Global Offset Table
不过说着轻松,想确定“我当前的地址”可不是件容易的事,比如有如下代码:
|
|
-shared告诉编译器生成so文件,-fPIC告诉编译器生成位置无关的代码,综合在一起就是生成位置无关的so文件,这两个通常配套使用。
这里foo是static的,所以它会保存在so文件的data段中。对于64位机(amd64),因为可以直接访问%rip,所以当前指令地址很好获得:
|
|
第三条是重点(其余不属于本文讨论范文),我们在上一节接触过类似的,按照相对位置%rip+0x2002b2,取到该地址处的内容(即data),将其赋给%eax。对于64位机,就这么简单。
但对于32位机(i386)的话,就要麻烦一些了,因为32位架构下接触不到PC。所以,需要一点小技巧:
|
|
0x40f处一个call指令调用__i686.get_pc_thunk.cx函数:先将call指令的下一条指令的地址(这里是0x414)压到栈上,然后蹦到这个函数地址处(0x422)开始执行:将刚刚压栈的下一条指令的地址赋给%ecx,然后ret到0x414继续执行add指令:0x115c + 0x414 = 0x1570。然后再到0x41a把0x1570 + 0x18 = 0x1588地址处的内容,给到%eax寄存器中。这里我们可以去看一下0x1588中写着什么:
|
|
值为0x0000000064=100,正是源码中static int 类型的变量foo的值100。
我们注意到,上面源码中foo是static的,即使属于该so文件本身的。那么,如果一个so文件,想去索引其他的so文件中的data怎么办?当然,我们可以patch这个so文件的代码部分,直接把那个data的位置为patch上,但这样就破坏了so文件的 code-sharability。而计算机中有一个原理就是:所有问题都可以通过加一个间接层来解决。这里,这个间接层就叫global offset table or GOT.
考虑下面情况:
|
|
这里foo是一个extern外部变量,大概来自什么其他的库文件吧。我们看一下在amd64架构上的情况吧:
|
|
我们可以看到返回值来自于%rip + 0x200271 = 0x200828。我们再看一下这个so文件的headers,可见0x200828属于.got范围内。然后,我们在看一下这个so文件的relocations,我们看到“R_X86_64_GLOB_DAT ”告诉链接器:“链接器啊,你去到其他对象文件中找一下foo的值,然后把它patch到0x200828这个位置”。
所以,当动态加载器加载该so文件时,会先去看它的relocations,然后找到foo的值,然后把它patch到该so文件的属于.got部分的0x200828地址处。当code段索引到foo这个值的时候,直接到.got的0x200828处去拿就好了,everything just works:code段也不需要修改,从而就没有破坏so文件的code sharability.
0x04 Procedure Linkage Table
上节我们可以处理so文件对外部变量的引用了,但如果是外部函数调用呢?此处,我们使用的“间接层”叫做procedure linkage table or PLT。code只会通过PLT stub(PLT桩代码,其实就是一小段代码),实现外部函数调用。如下例子:
|
|
执行function这个函数时,我们看到有一句callq指令,从而执行流跳到0x4d0处执行,该处为jmpq *0x200382(%rip),即以0x200382 + 0x4d6 = 0x200858地址处取内容作为地址,进行跳转。那么我们看一下第一次这么执行时,0x200858处的内容是什么:
|
|
jmpq是quadra word,即8个字节,所以取0x00000000000004d6(即从地址0x200858到0x20085f地址,取这8个字节,注意小端模式,所以倒着写)。这恰好是jmpq的下一条指令的地址(注意,这是第一次call foo这个外部函数时的情形)。0x4d6的指令是,push $0x0,这里这个push的0是foo这个函数符号在.rela.plt数据结构中的下标(也可称为索引或者index),用于定位这个foo这个符号(具体参见《程序员的自我修养》,估计以后我也会专门写一篇有关对象文件构成的文章)。执行完push后,就jmp到了0x4c0这个位置,我们看一下0x4c0处写了什么:
|
|
又push了一个值,这个值是什么呢?在后面注释中我们可以看到_GLOBAL_OFFSET_TABLE_+0x8这种字样,它又是什么呢?
我先查阅了CSAPP,看到了如下内容:
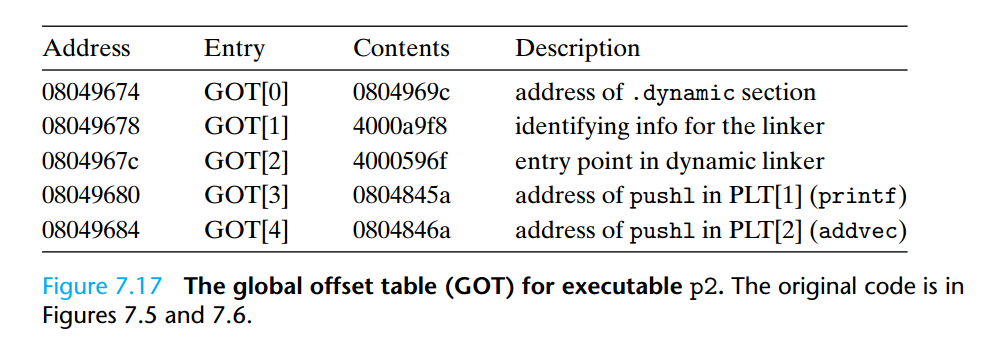
然后,查阅了《程序员的自我修养》,看到如下内容:

所以,我的理解是,我们可以把_GLOBAL_OFFSET_TABLE_理解成为一个类似数组一样的东西,每个元素保存着一个地址,32位机就是4字节地址,64位机就是8字节地址。
所以_GLOBAL_OFFSET_TABLE_+0x8就是_GLOBAL_OFFSET_TABLE_的第二个元素,参考上面两幅图片可知,这个代表了libtest.so(即模块的ID),_GLOBAL_OFFSET_TABLE_+0x10则为_GLOBAL_OFFSET_TABLE_的第三个元素,为动态解析函数的入口地址。
然后在0x4c6,跳到这个动态解析函数,开始对foo这个函数名进行解析,找到其地址,并patch到0x200858这个位置(这个位置在GOT中),从而第二次调用foo的时候,jmp的地址就不是0x00000000000004d6了,而是foo的实际地址了。
这种,第一次调用foo函数,通过PLT stub(PLT桩代码)进行动态链接(地址解析),找到foo函数真实地址并patch GOT表,第二次直接通过PLT桩代码跳到foo函数真实地址的方式,称为“延迟绑定技术”(lazy binding)。
好了,以上便是PLT技术的一些细节实现。另外多说一句,我们可以在运行某使用so库的可执行文件时,使用LD_PRELOAD 来修改动态链接时,符号解析的顺序。也就是说,LD_PRELOAD会告诉动态链接器,想找什么符号的话,先从这里找,如果LD_PRELOAD中所提供so库里有foo这个符号,那么动态链接器会首先到这里找foo的地址,而不会去其他so库中去找。
0x05 Summary
so库的代码段要保持只读,而且数据段也要为各个进程所私有。需要在编译时通过已知的各个符号的偏移量,建立GOT和PLT表,从而间接地达成第一句的目标。